Training a char-rnn to Talk Like Me
04 Feb 2017Someone recently suggested to me the possibility of training a char-rnn on the entire history of my Facebook conversations. The idea would be to see if the result sounds anything like me. When I first started out, my idea was simply to use one of the existing char-rnn implementations, for example this one written using Torch, or this one, written using Lasagne and Theano. Along the way, however, I decided that it would be a good learning experience to implement a char-rnn myself. If you’re only interested in the code, it’s available on Github.
As a result, this post now consists of two parts. The first provides a very brief overview of how a char-rnn works. I keep it brief because others have already done excellent work to provide extensive insights into the details of a char-rnn, for example, see this blog post by Andrej Karpathy. The second describes how I trained this char-rnn on my own Facebook conversations, and some of the things I discovered.
Background of char-rnn
In this section, I’ll provide a very brief overview of how a char-rnn works. If you’re interested in an extensive discussion instead, I recommend that you rather read the blog post mentioned above.
The term “char-rnn” is short for “character recurrent neural network”, and is effectively a recurrent neural network trained to predict the next character given a sequence of previous characters. In this way, we can think of a char-rnn as a classification model. In the same way that we output a probability distribution over classes when doing image classification, for a char-rnn we wish to output a probability distribution over character classes, i.e., a vocabulary of characters. Unlike image classification where we are given a single image and expected to predict an output immediately, however, in this setting we are given the characters one at a time and only expected to predict an output after the last character. This is illustrated below. Consider the sequence of characters, “Hello darkness my old friend”, where the sequence of characters marked in bold are observed by the model. At each step, the model observes a sequence of eight characters (show on the left) and is asked to predict the next one (on the right).

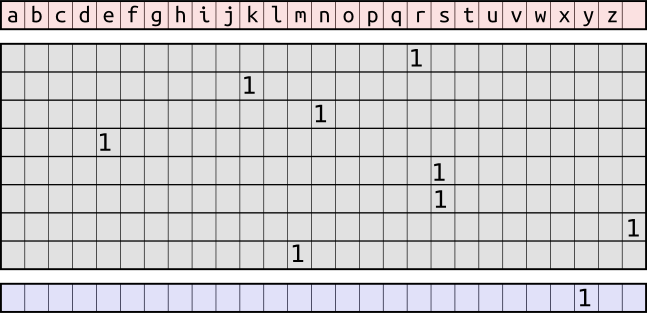
In practice, each character is typically encoded as a one-hot vector, where the position of the one indicates the position of the character in the vocabulary. For example, in a vocabulary consisting of the twenty-six lower-case letters and space, the first row of the sequence above would be encoded as demonstrated in the figure below. Note that zeros are represented by empty cells to reduce clutter. The top row shows the characters in the vocabulary, the grid shows each character in the sequence converted to its one-hot representation, and the bottom row shows the target character’s one-hot representation.
Because this is effectively a classification task, where the output classes are characters in the vocabulary, we use the standard categorical cross-entropy loss to train the model. If we let $\mathbf{y}$ be a vector representing the one-hot encoding of the target character and $\mathbf{\hat{y}}$ the vector of probabilities over the $n$ characters in the vocabulary as produced by the output layer of the char-rnn, then the loss for a single target character is defined as $-\sum\limits_{i=1}^{n}y_i\log(\hat{y}_i)$.
By iteratively minimizing this loss, we obtain a model that predicts characters consistent with the sequences observed during training. Note that this is a fairly challenging task, because the model starts with no prior knowledge of the language being used. Ideally, this model would also capture the style of the author, which we explore next.
Training a char-rnn on my Facebook Conversations
After implementing a char-rnn as described above, I decided to train it on the entire history of my Facebook conversations. To do this, I first downloaded my chat history. This can be achieved by clicking on “Privacy Shortcuts”, “See More Settings”, “General”, and finally “Download a copy of your Facebook data”. These instructions are available here.
Next, clone this Facebook chat parser and install it:
git clone https://github.com/ownaginatious/fbchat-archive-parser
python setup.py developNow unzip the downloaded archive and parse it. The filepath should point to the messages.htm file inside the unzipped archive.
fbcap html/messages.htm > messages.txtAt this point, you have a text file messages.txt containing the data, sender, and text
of every message from your Facebook conversation history. To train the
char-rnn, however, I wanted to train only on messages written by me. To
do this, I used the this code snippet to parse out messages
indicating me as the sender. You can use this snippet too, or write your
own, more sophisticated parser if you want more control over which
messages to use for the training data.
Finally, set the text_fpath variable in the train_char_rnn.py file, and run python train_char_rnn.py. At first, the output will be mostly gibberish, with alternating short words repeated for the entire sequence. I started seeing somewhat more intelligible output after about twelve hours of training on an NVIDIA TITAN X.
Results
After training the model on the entire history of my Facebook conversations, we can generate sequences from the model by feeding an initial sequence and then repeatedly sampling from the model. This can be done by using the generate_samples.py file. Set the text_fpath to the same text file used to train the model (to build the vocabulary), and run python generate_samples.py.
Next, we show some samples from the model. The phrase used to initialize the model is shown in italics.
-
The meaning of life is to find them? Oh, I don’t know if I would be able to publish a paper on that be climbing today, but it will definitely know what that makes sense. I’m sure they wanted to socialis that I am bringing or
-
What a cruel twist of fate, that we should be persuate that 😂 And cook :D I will think that’s mean I think I need to go to the phoebe? That’s awesome though Haha, sorry, I don’t know if it was more time to clas for it’s badass though I jus
-
The fact of the matter is just the world to invite your stuff? I don’t know how to right it wouldn’t be as offriving for anything, so that would be awesome, thanks :) I have no idea… She would get to worry about it :P And I
-
At the very least, you should remember that as a house of a perfect problems 😂 Yeah :D I wonder how perfect for this trank though So it’s probably foltower before the bathers will be fine and haven’t want to make it worse Thanks for one of
Looking at these samples, it would appear as if the model has learned decent spelling and punctuation, but struggles to formulate sensible sentences. I suspect that the training data was too limited, as the entire text file is only about 1.5MB. Additionally, unlike email, Facebook messages often consist of short replies rather than multiple, full sentences. At the end of the day, I highly doubt I could fool anyone by having the char-rnn auto-reply to them. On the other hand, I don’t think releasing a model that’s been trained on every message I’ve ever sent would be a good idea either.