Efficient Image Loading for Deep Learning
06 Jun 2015When doing any kind of machine learning with visual data, it is almost always necessary first to transform the images from raw files on disk to data structures that can be efficiently iterated over during learning. Python’s numpy arrays are perfect for this.
The Lasagne neural network library, of which I’ve grown very fond, expects the data to be in four-dimensional arrays, where the axes are, in order, batch, channel, height, and width.
The Naïve Way
Previously, I have always simply loaded the images into a list of numpy arrays, stacked them, and reshaped the resulting array accordingly. Something like this:
for fpath in fpaths:
img = cv2.imread(fpath, cv2.CV_LOAD_IMAGE_COLOR)
image_list.append(img)
data = np.vstack(image_list)
data = data.reshape(-1, 256, 256, 3)
data = data.transpose(0, 3, 1, 2)However, this comes with a higher-than-necessary memory usage, for the simple reason that numpy’s vstack needs to make a copy of the data. For a small dataset, this might be fine, but for something like the images from Kaggle’s Diabetic Retinopathy Detection challenge, we need to be much more conservative with memory. In fact, even after I resized all 35126 images to 256x256, they still used 587MB of hard drive space. While this might not seem like much, consider that jpeg images are compressed. When we actually load these color images into memory we will need to allocate 3 bytes per pixel - one for each color channel. Thus, we need 35126x3x256x256 = 6.43 GB to store them in numpy arrays. Suddenly I realized that my workstation would not be able to apply a vstack to the image data without using swap memory.
The Better Way
Fortunately, we can avoid this by pre-allocating the data array, and then loading the images directly into it:
data = np.empty((N, 3, 256, 256), dtype=np.uint8)
for i, fpath in enumerate(fpaths):
img = cv2.imread(fpath, cv2.CV_LOAD_IMAGE_COLOR)
data[i, ...] = img.transpose(2, 0, 1)
Evaluation
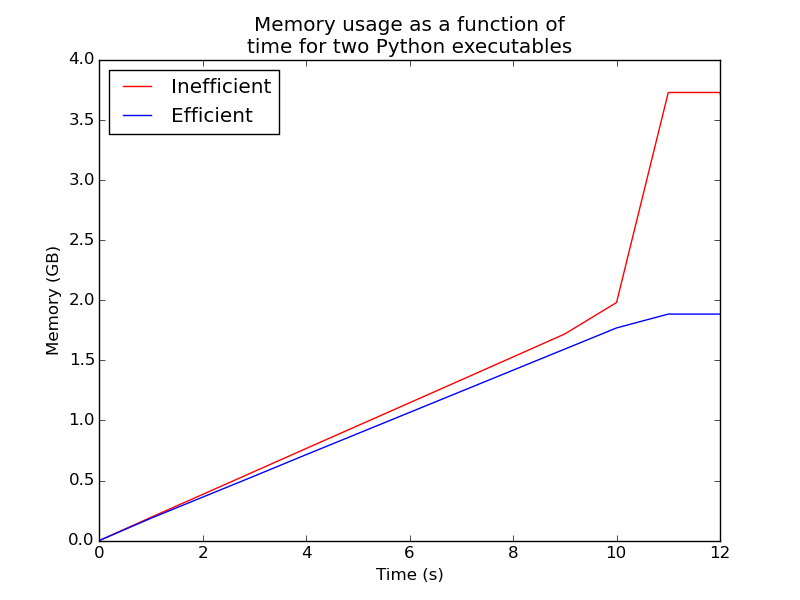
We can demonstrate the improved memory usage by inspecting the memory usage of the two
functions. Below we load 10000 RGB images, each of dimensions 256x256, into memory. This should require approximately 10000x256x256x3 = 1.83 GB of memory using our improved technique. Note how the memory usage for the first snippet roughly
doubles when the copy is made.
Conclusion
It is not a daily occurrence to halve memory usage with such a simple trick. This solution in its simplicity and elegance helps to free some valuable resources when doing learning, which is already quite computationally intensive by itself.