In practice, initializing the weight matrix of a dense layer to a random
orthogonal matrix is fairly straightforward. For the convolutional layer,
where the weight matrix isn’t strictly a matrix, we need to think more carefully about what this
means.
In this post we briefly describe some properties of orthogonal
matrices that make them useful for training deep networks, before discussing
how this can be realized in the convolutional layers in a deep convolutional
neural network.
Introduction
Two properties of orthogonal matrices that are useful for training deep neural networks are
they are norm-preserving, i.e., $||Wx||_2 = ||x||_2$, and
their columns (and rows) are all orthonormal to one another, i.e., $w_{i}^Tw_{j} = \delta_{ij}$, where
$w_{i}$ refers to the $i$th column of $W$.
At least at the start of training, the first of these should help to keep the norm of the input
constant throughout the network, which can help with the problem of exploding/vanishing gradients.
Similarly, an intuitive understanding of the second is that having orthonormal weight vectors encourages
the weights to learn different input features.
Dense Layers
Before we discuss how the orthogonal weight matrix should be chosen in the convolutional layers, we
first revisit the concept of dense layers in neural networks. Each dense layer contains a fixed
number of neurons. To keep things simple, we assume that the two layers $l$ and $l+1$ each have $m$ neurons.
Let $W$ be an $m \times m$ matrix where the $i$th row contains the weights incoming to neuron $i$ in layer $l+1$,
$\mathbf{x}$ be a $m \times 1$ vector containing the $m$ outputs from the neurons in layer $l$, and $\mathbf{b}$ be the
vector of biases. Then we can describe the pre-activation of layer $l+1$ as $\mathbf{z}$,
where the activation function $f(\mathbf{z})$ is applied to
produce the final output of layer $l+1$. In the following figure we show how
the outputs from the previous layer, $x_1, \ldots, x_j, \ldots, x_m$, are multiplied
by the $i$th neuron’s weights, $w_1, \ldots, w_j, \ldots, w_m$, the bias is added, and
the activation function applied.
In this formulation, the idea behind orthogonal
initialization is to choose the weight vectors associated with the neurons in layer
$l+1$ to be orthogonal to each other. In other words, we want the rows of $W$ to be orthogonal
to each other.
Convolutional Layers
In a convolutional layer, each neuron is sparsely connected
to several small groups of neurons in the previous layer. Even though each convolutional kernel
is technically a $k \times k$ matrix, in practice the convolution can be thought of as an inner product
between two $k^2$-dimensional vectors, i.e.,
$\mathbf{x} \ast \mathbf{w} = \sum\limits_{i=1}^{k^2}x_i \cdot w_i$.
Below we show how a different convolutional kernel is applied to each channel in layer $l$, the results summed, the bias added,
and the activation function applied.
Now it becomes clear that we should choose each channel in layer $l+1$ to have
a “weight vector” that is orthogonal to the weight vectors of the other
channels. When we say “weight vector” in the convolutional layer, we really
mean the kernel-as-vector for each of the channels stacked next to each other.
This is similar to how it was done in the dense layer, but now the weight
vector is no longer connected to every neuron in layer $l$.
Implementation
We can check this intuition by examining how the orthogonal weight initialization is implemented in
a popular neural network library such as Lasagne. Suppose
we want a matrix with $m$ rows, with $m$ the number of channels in layer $l+1$, where the rows are all
orthogonal to one another. Each row is a vector of dimension $nk^2$, where $n$ is the number of channels in
layer $l$, and $k$ is the dimension of the convolutional kernel. For practical purposes, let us choose
$m = 64$, $n = 32$, and $k = 3$, i.e., layer $l + 1$ has $64$ channels, each learning a $3 \times 3$ kernel for
each of the $32$ channels in layer $l$.
Similar to how it’s implemented in
Lasagne,
we can use the Singular Value
Decomposition
(SVD). Given a random matrix $X$, we compute the reduced SVD, $X =
\hat{U}\hat{\Sigma}\hat{V}^T$, and then use the rows of the matrix $V^T$ as our
orthogonal weight vectors (in this case the weight vectors are also
orthonormal). So, in Python:
Finally, we can use the matrix $W$ to initialize the weights of the convolutional layer. Keep in mind, however,
that in practice the elements of $W$ are often scaled to compensate for the change in norm brought about by the
activation function.
Conclusion
Orthogonal initialization has shown to provide numerous benefits for training deep neural networks.
It is easy to see which vectors should be orthogonal to one another in a dense layer, but less straightforward
to see where this orthogonality should happen in a convolutional layer, because the weight matrix is no longer
really a matrix. By considering that neurons in a convolutional layer serve exactly the same purpose as
neurons in a dense layer but with sparse connectivity, the analogy becomes clear.
Very interesting paper where the idea of
using unitary matrices, $W^*W = I$ with $*$ indicating the conjugate
transpose, in recurrent
neural networks is investigated to avoid the problem of vanishing and exploding
gradients.
I recently participated in Kaggle’s
Grasp-and-Lift EEG Detection, as part
of team Tokoloshe (Hendrik Weideman and Julienne LaChance).
None of the team members had ever used deep learning for EEG data, and
so we were eager to see how well techniques that are generally applied to problems in computer
vision and natural language processing would generalize to this new domain. Overall, it was a
fun challenge to work on and gave us a renewed appreciation for the wide range of problem domains
that could potentially benefit from the incredible progress recently made in deep learning research.
Those wishing to skip ahead might be interested in the following key sections:
Patients who have suffered from amputation or other neurological disabilities often have
trouble performing tasks that are an essential part of everyday life. Research in devices
like brain-computer interfaces
aims to provide these people with prosthetic limbs that may be controlled by means of an
interface to the brain. Ideally, this would enable these people to regain abilities that
are often taken for granted, thereby providing them with greater mobility or independence.
Problem Statement
The goal of the challenge is to predict when a hand is performing each of six different actions given
electroencephalography (EEG) signals. The EEG signals are obtained from sensors placed on a subject’s head, and the
subject is then instructed to perform each of the six actions in sequence.
The Data
We are provided with EEG signals for 12 different subjects, each consisting of 10 series of trials.
Each series consists of a variable number of trials, but typically around 30. One trial is defined
as the progressive sequence of actions from the first to the sixth action. The six actions that
we wish to predict are
HandStart
FirstDigitTouch
BothStartLoadPhase
LiftOff
Replace
BothReleased
In particular, the EEG signal for each trial consists of a real value for each of the 32 channels
at every time step in the signal. The subject’s EEG responses are sampled at 500 Hz, and so the
time steps are 2ms from each other. For each time step, we are provided with six labels, describing
which of the six actions are active at that time step. Note that an action is labeled as active
if it occurred within 150ms of the current time step (future or past). The implication of this is that multiple
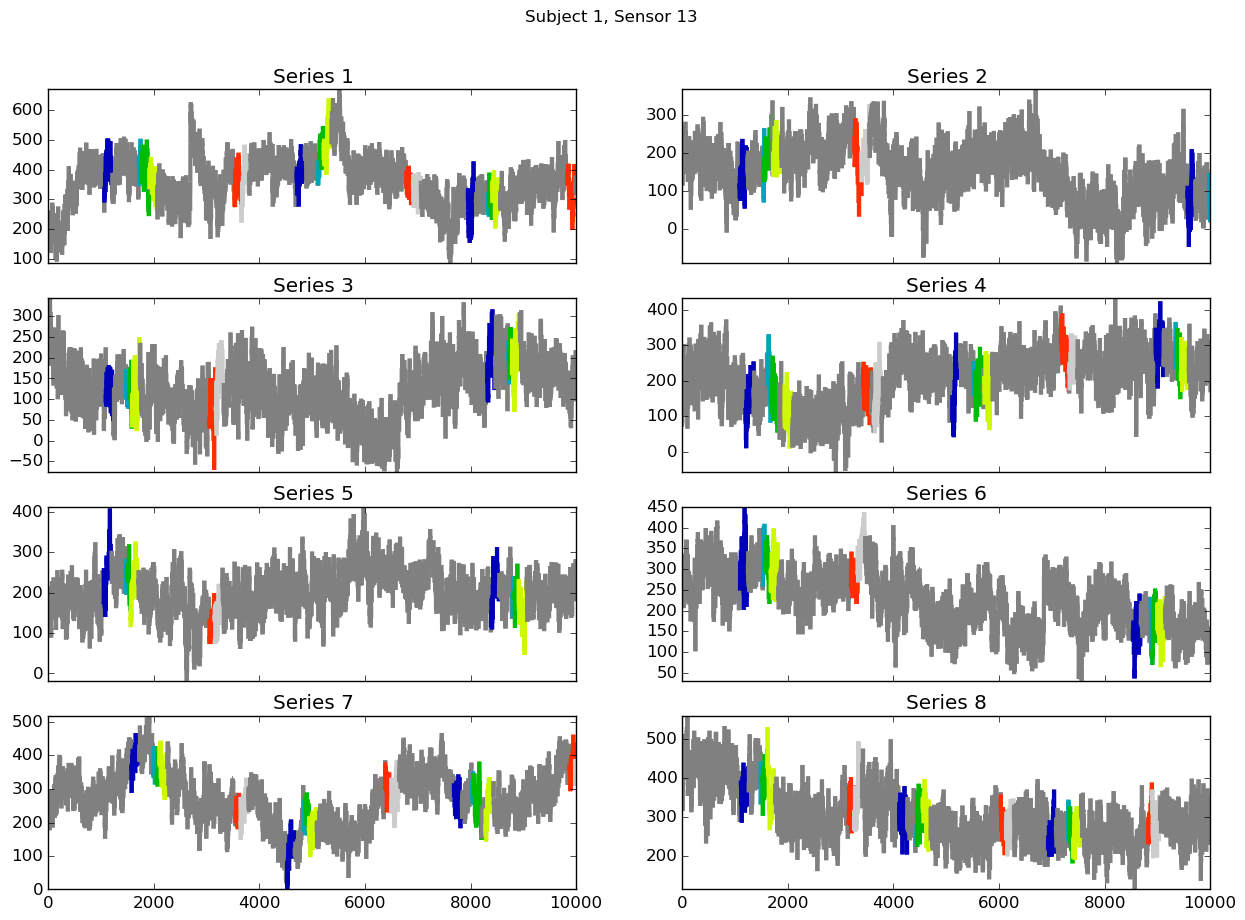
actions may be labeled as active simultaneously. Below we show the eight series from sensor 13 for subject 1 provided for
training. The colors indicate the different actions, gray indicates that no action is active. Note the amount
of variation between the signals, even for a single sensor and a single subject.
Because we are working with time data, it is critical to note that we are not allowed to
use data from the future when making predictions. It is simpler to think of this in terms of the practical
usage of such a system - when predicting the action that a user is performing, the system will not
have access to EEG signal responses that have not occurred yet. In practice, this means that
we are free to train on any of the training data that we want. However, when we make a prediction
for a particular time step in the test set, we may only use EEG responses from time steps that
occurred at or before that time step. This is important to keep in mind, because we are provided
with the EEG responses for all time steps in the test set. Care should be taken that these are in
no way used when making submissions to the competition (such as when centering or scaling the signals).
As with all machine learning problems, there are some challenges with this data set. Primarily,
EEG signals are notoriously noisy, and we are given 32 channels, several of which likely do not
correlate well with which of the actions are active. Additionally, the signals vary considerably
from person to person and even series to series.
Our Team’s Solution
Given that our primary goal of participating in this challenge was to explore a new problem domain
using deep learning, we wanted to build a system that is neither subject nor action-specific. Thus,
our system is trained to predict actions given EEG signals, with no regard for which person or action
it is working with. We also experimented with subject-specific models, but achieved worse performance.
We suspect that the additional data from other subjects helps to regularlize the very large capacity
of our deep learning models, thereby improving generalization across all subjects and actions.
Data Preparation
To build our training set, we chunk the EEG signals into fixed length sequences, that we refer to as
time windows. We label each time window with six binary values indicating which of the six
actions are active at the time step corresponding to the last time step in the time window. To
normalize the data, we subtract the mean computed over all series from all subjects, and divide
by the standard deviation computed similarly. For validation data, we keep two series from each
subject separate and train on the remaining six. We do this so that we can monitor that our
model is not fitting certain subjects while neglecting others.
System Architecture
Below we describe the implementation of our solution.
Deep Convolutional Neural Network
Our deep convolutional neural network has eight one-dimensional convolutional layers,
four max-pooling layers, and three dense layers. The final dense layer has six output neurons, each with
a sigmoid activation function that predicts the probability that a given action is active. We use
the rectified linear unit (ReLU) as the activation
function in all layers except for the output layer. Dropout
with p = 0.5 is applied in the first two dense layers.
Input
We use time windows of 2000 time steps, that is, each time window observes four seconds of EEG signal. As described
below, we subsample this time window so that only 200 time steps are actually used when feeding the example to the
deep convolutional neural network.
Loss
Because the challenge’s evaluation metric, the
mean column-wise area under the ROC curve, is not differentiable, we instead minimize the
binary cross-entropy loss, taking
the mean across the loss for each of the six actions. Even though these two are not exactly equivalent, minimizing this loss function
should generally lead to better performance on the challenge’s evaluation metric.
Implementation
Our solution uses Lasagne and Theano
for the implementation of the convolutional neural network. We also use scikit-learn,
pandas, and matplotlib for various utilities. We developed our
solution using Ubuntu 15.04. The code is available on GitHub.
Hardware
We trained our deep convolutional neural network on a computer with an NVIDIA Quadro K4200 and 16GB of RAM.
Performance Tricks
While designing our model, there were a few simple tricks that we came up with that improved our model’s performance
on the held-out validation data. These are briefly described below.
Subsampling Layer
When feeding each time window into the deep convolutional neural network, we first subsample every Nth point.
Not only does this greatly reduce the computational burden, but it also helps to reduce overfitting. Our
initial idea was to use this as a form of data augmentation, where we would sample every Nth point starting
from different time steps in the time window, but this did not seem have any effect.
Window Normalization Layer
We found that normalizing the values in each time window to be between 0 and 1 greatly improved generalization.
This was done by simply using the minimum and maximum values in each time window to compute a transformation to
the desired range. We suspect that this is because the relative difference between points in the time window
is more important than the actual amplitudes, and so by normalizing for this difference we encourage the model
to fit the actual signal, rather than the noise.
Results
Our final solution earned us a spot in the Top 10% on the challenge’s
private leaderboard.
Other Ideas
Throughout this challenge, we had numerous other ideas that we could never quite get to work. One in particular
was the concept of data augmentation, which is the generation of more training examples by transforming
existing training examples in such a way that the relationship to the corresponding label is preserved. There
were two key ideas that we tried, namely
subsample each time window from a random starting position, so that the network only occasionally sees the exact
time window twice, and
increase the number of positive training examples (training examples where an action is active) by duplicating
existing training examples, where each duplicated example gets a small amount of Gaussian noise added to it.
Unfortunately, neither of these ideas enabled our model to generalize better to unseen test data.
Final Words
We are very excited to see the scores achieved on the challenge’s leaderboard, as this certainly indicates that
deep learning has the potential to contribute to further progress in the field of brain-computer interfaces and
the analysis of EEG signals. We would also like to congratulate the top three teams:
Anyone interested in their solutions may follow the above links to their own descriptions of their solutions.
Finally, we would also like to give special thanks to Alexandre Barachant
from team Cat & Dog,
for publicly sharing so much of his knowledge related to brain-computer interfaces and EEG signals.
Often when I want to use Ubuntu’s eye of gnome image viewer to view image files,
I find that it becomes very slow and unresponsive when trying to open an image
in a directory containing many other images. Recently I decided to look for an
alternative. I wanted something minimal that would open images quickly and
without fuss, and this is when I discovered feh.
feh
feh is an incredibly lightweight image viewer that can be used from the terminal.
Simply pass the filename of an image or directory as an argument, or even a text file
containing a list of filenames, and it will open the images one-at-a-time for viewing.
Installing is as simple as
sudo apt-get install feh
Montages
Despite its minimalism, feh has some nice features. Creating a montage is as simple as running
feh -m images/ -b trans -W 200
where an optional background file (or trans, for transparent) can be specified with the -b flag, and the width
of the montage can be limited with the -W flag. As shown below, feh nicely tiles the images in a grid,
even when they are of different shapes and sizes.
Labeling Images
More related to the topic of machine learning, it is also possible to sort images into categories using feh.
This is especially useful for quickly creating a dataset of class-labeled images when
developing a learning model. feh allows you to specify an action, which will
execute every time a key is pressed. So using this simple bash script, it is possible
to iterate over all images in a directory, and copying them to the appropriate directory
by pressing the number keys.
#!/usr/bin/env bash
feh \--cycle-once\--action1\"cp '%f' ~/data/cats/%n"\--action2\"cp '%f' ~/data/dogs/%n"\--action3\"cp '%f' ~/data/birds/%n"\--action4\"cp '%f' ~/data/bears/%n"\"$1"# this is the directory from which to read images
This script may be run as ./feh_labeling.sh ~/data/all-images/, and by pressing keys 1 through 4,
the currently shown image may be copied to the corresponding directory. More sophisticated tasks are
also possible using feh’s actions, for more information see the Ubuntu manual entry.
Conclusion
Thanks to its quick response time and flexible features, feh has now replaced eye of gnome as my image
viewer of choice. Despite its apparent minimalism, it provides some very useful features for
boosting productivity when working with image files.
When doing any kind of machine learning with visual data, it
is almost always necessary first to transform the images from
raw files on disk to data structures that can be efficiently
iterated over during learning. Python’s numpy arrays
are perfect for this.
The Lasagne neural network library, of which I’ve grown very fond,
expects the data to be in four-dimensional arrays, where the axes
are, in order, batch, channel, height, and width.
The Naïve Way
Previously, I have always simply loaded the images into a list of
numpy arrays, stacked them, and reshaped the resulting array
accordingly. Something like this:
However, this comes with a higher-than-necessary memory usage, for
the simple reason that numpy’s vstack needs to make a copy of the data.
For a small dataset, this might be fine, but for something like the
images from Kaggle’s Diabetic Retinopathy Detection challenge, we need
to be much more conservative with memory. In fact, even after I resized
all 35126 images to 256x256, they still used 587MB of hard drive space.
While this might not seem like much, consider that jpeg images are compressed.
When we actually load these color images into memory we will need to allocate 3 bytes per pixel - one for each color channel. Thus, we need 35126x3x256x256
= 6.43 GB to store them in numpy arrays. Suddenly I realized that my
workstation would not be able to apply a vstack to the image data without
using swap memory.
The Better Way
Fortunately, we can avoid this by pre-allocating the data array, and then loading
the images directly into it:
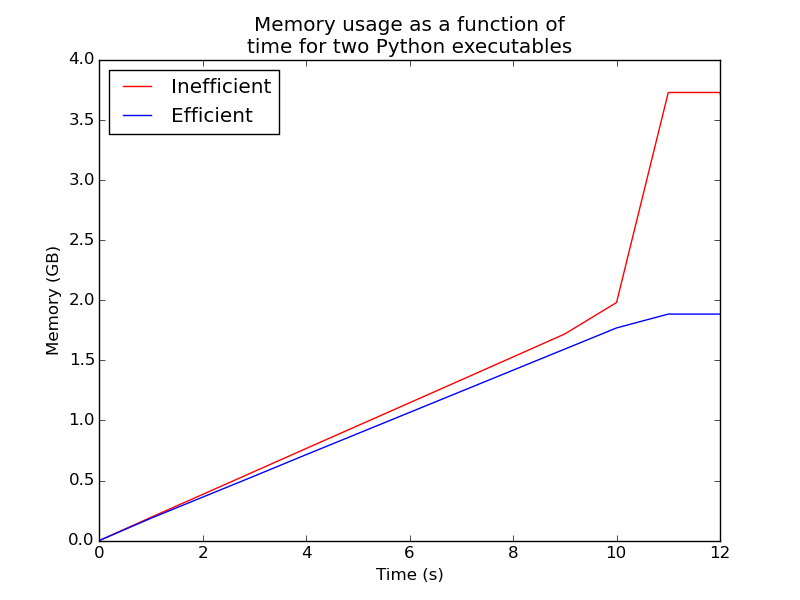
We can demonstrate the improved memory usage by inspecting the memory usage of the two
functions. Below we load 10000 RGB images, each of dimensions 256x256, into memory. This should require approximately 10000x256x256x3 = 1.83 GB of memory using our improved technique. Note how the memory usage for the first snippet roughly
doubles when the copy is made.
Conclusion
It is not a daily occurrence to halve memory usage with such a simple
trick. This solution in its simplicity and elegance helps to free
some valuable resources when doing learning, which is already quite
computationally intensive by itself.